Smart Bulb Rant: Avoid Bluetooth + Alexa Bulbs
 Having worked with a number of smart Internet of Things devices (IoT), mostly light bulbs and hubs, I’ve come to learn what works and what doesn’t. Let’s explore.
Having worked with a number of smart Internet of Things devices (IoT), mostly light bulbs and hubs, I’ve come to learn what works and what doesn’t. Let’s explore.
Smart Hubs
Overall, the smartest value for your money is the purchase of a smart hub with light bulbs, such as the Philips Hue system. Why? These smart hubs use a mesh network that is separate from your WiFi network. These systems also have their own custom iOS apps that allow for extreme customization of colors, scenes and grouping. These hub-based devices also don’t require or consume IP addresses, like WiFi bulbs, but there are drawbacks to using a smart hub based system.
The biggest drawback is that smart hubs require an active Internet connection be available 24×7. When the Internet goes down, the smart devices, including light bulbs, don’t work well or at all. This is where WiFi bulbs typically shine, though not always. Controlling WiFi bulbs almost always works even with the Internet down when the mobile app is written properly. However, some mobile apps must check in with the mothership before enabling remote control features. Which means… the lack of Internet connectivity makes it difficult to control your devices other than manually. The good news is that most of these light bulbs work correctly by using the light switch on the lamp. This means you can still turn lamps on and off the “old fashioned way” … assuming you have electric power, of course.
The second drawback is that these systems are subject to interference by certain types of wireless systems such as some Bluetooth devices, wireless routers and cordless phone systems.
However, to be able to utilize voice control, such as with Google Home, Alexa or Apple’s Siri, this requires the Internet. The same for most smart apps. Though, I have found that Hue’s iOS or Android app can sometimes control lighting even with the Internet offline. However, without the Internet, the hub may perform poorly, work intermittently or fail to take commands until the Internet is restored.
While the Internet is online and functional, however, control of lighting and devices is easy and seamless. Not always so with…
Bluetooth and Alexa
Recently, some IoT LED bulb manufacturers have begun designing and using smart LED light bulbs based strictly on Bluetooth combined with Alexa. These Bluetooth based lights also don’t require or consume IP addresses, unlike WiFi bulbs. After all, Echo devices do support Bluetooth to allow for connecting to and controlling remote Bluetooth devices. The problem is, the Echo’s Bluetooth can be spotty, at best. Mostly the reason that Bluetooth is spotty is that it uses the same frequency as many home cordless phone systems (as well as WiFi routers and other Bluetooth devices). Not cell phones, mind you, but those old 2.4Ghz cordless handsets that sit in a charging base. Because these phone systems burst data periodically to keep the remote handsets up-to-date, these bursts can interfere with Bluetooth devices. Note that this can be major a problem if you live in a condo or apartment where adjacent neighbors could have such cordless phone systems or routers. Unfortunately, these bulbs can end up being problematic not only because of cordless phones.
Likewise, if you live in a large house with a number of different Echo devices on multiple floors (and you also have these cordless phone handsets), the bulb randomly chooses an Echo device to connect to as its Bluetooth ‘hub’. Whenever a command is issued from any Echo to control that light bulb, these devices must contact this elected Echo ‘hub’ device to perform the action. This could mean that the light bulb has hubbed itself to the farthest device from the bulb with the worst connection. I’ve seen these bulbs connect to not the closest Echo device to the bulb, but the farthest. As an example, I have a small Echo dot in the basement and this is the unit that tends to be elected by these bulbs when upstairs. This is also likely to have the most spotty connection and the worst Bluetooth reception because of being in the basement. There’s no way to ensure that one of these bulbs chooses the best and closest device without first turning off every Echo device except the one you want it connected to… a major hassle.
In the end, because the bulb chooses randomly and poorly, you’ll end up seeing ‘Device Malfunction’ or ‘Device Not Responding’ frequently inside of the Alexa app. If you click the gear icon with the device selected, you can see which Echo device the bulb has chosen. Unfortunately, while you can see the elected device, you cannot change it. The ‘Device Malfunction’ or ‘Device Not Responding’ messages inside of the Alexa app mean that the Alexa device is having trouble contacting the remote device, which is likely because of interference from something else using that same frequency (i.e., cordless handsets or routers).
This makes the purchase of any Bluetooth only LED light bulbs an exceedingly poor choice for Alexa remote control. Amazon can make this better by letting the user change the hub to a closer unit. As of now, the Alexa app doesn’t allow this.
Hub based Systems
Why don’t hub based systems suffer from this problem? Hub based systems setup and use a mesh network. What means is that the devices can all talk to one another. This means that instead of each device relying on directly connecting to the hub, the devices link to one another to determine which device in the mesh has the best connection to the hub. When the hub issues commands, it goes the other way. The command is sent down the mesh chain to a better connected device to issue the command to the destination bulb. This smart mesh network makes controlling lights via a hub + mesh system much more reliable than it would otherwise be without this mesh. The Philips Hue does use 2.4Ghz also to support the ZigBee protocol, but the smart mesh system prevents many connectivity problems, unlike these Sengled Bluetooth LED bulbs.
This is exactly why purchasing a Bluetooth-based light is a poor choice. Because these BT light bulbs don’t have enough intelligence to discover which Echo device is closest and has best connectivity and because it cannot talk to just any Echo device, this leaves the light bulb prone to problems and failure.
Sure, these BT bulbs may be less costly than a Hue bulb, but you get the quality you pay for. Alexa’s Bluetooth was not designed or intended for this type of remote control purpose. It’s being sledgehammered into this situation by these Chinese bulb manufacturers. Sure, it can work. For the most part, it fails to work frequently and often. It also depends on the bulb itself. Not all bulb electronics are manufactured equally, particularly when made in China.
If you find a specific bulb isn’t working as expected, the bulb is probably cheaply made of garbage parts and crappy electronics. You’ll want to return the bulb for replacement… or better, for a Hue system / bulb.
Color Rendition
These cheap bulb brands include such manufacturers as Sengled (shown in the photo) … a brand commonly found on Amazon. Because these bulbs are made cheaply all around, but separate from the BT issues already mentioned, you’ll also find the color rendition on these LED bulbs to be problematic. For example, asking for a Daylight color might yield something that ends up too blue. Asking for Soft White might end up with something too yellow (or a sorry shade of yellow). These are cheap bulbs made of exceedingly cheap parts through and through, including cheap LEDs that aren’t properly calibrated.
Asking for Yellow, for example, usually yields something more closely resembling orange or green. That would be fine if Alexa would allow you to create custom colors and name them. Unfortunately, the Alexa app doesn’t allow this.
Whatever colors are preset in Alexa are all the colors you can use. There are no such thing as custom colors inside of Alexa. If you don’t like the color rendition that the bulb produces, then you’re stuck. Or, you’ll need to replace the bulb with one that allows for custom color choices.
Bulbs purchased for a hub based system, like the Philips Hue bulbs, typically offer a custom iOS or Android app that allows for building not only custom colors and presets, but also custom scenes that allow for setting individual bulbs separately, but as a group. The Alexa app wasn’t designed for this granular lighting control purpose and is extremely lean of options. Everything that the Alexa app offers is set in stone and extremely rudimentary for lighting control. The Alexa app is designed as a can-opener, not as a specific tool. It does many things somewhat fine, but it doesn’t do any one thing particularly well.
Purchasing these BT Alexa-controlled LED lights is a poor choice overall. If you want the flexibility of color choices and color temperatures, you buy a bulb system like Philips Hue, which also offers a custom app. If you’re looking for something on-the-cheap but which allows quick control, then a Sengled or Cree or GE smart bulb might fit the bill. Don’t be surprised when the bulb fails to control at all or produces a color that is not what you were expecting. Worse, don’t be surprised when the bulb’s LED driver fails and begins to flash uncontrollably after a month’s use.
Updated Dec 7th after Amazon Outage
Today, Amazon Web Services (AWS) had a severe outage that impacted many different services including Ring and, yes, Amazon’s Smart Home features, including Alexa + Sengled bulbs. In fact, the only system that seems to have remain unaffected (at least in my home) was the Philips Hue system. Alexa was able to properly control all of my Philips Hue lights all throughout the day.
However, Alexa failed to control Kasa, Wemo, Wyze and even its own Bluetooth bulbs like Sengled. Indeed, pretty much most of my lights were unable to be controlled by Alexa throughout the duration of the outage, which was pretty much all day.
Amazon was able to isolate the failure root cause, but it still took them hours to recover all of the equipment needed to regain those services. This failure meant that it was impossible to control smart lights or, indeed, even my Ring alarm system.
Smart lights are controllable by switch. Shutting the switch off and back on will illuminate the light. You can then switch it off like normal. However, that also means that if the switch is off, Alexa can’t control the light. You must leave all lamp fixtures in the on position for the lights to turn on, off and dim by Alexa. If you turn the light switch off, then the smart features are no longer available and the lamp will display “Device is Unresponsive” in the Alexa app.
Failures
In fact, this “Device is Unresponsive” error is the exact failure response I saw throughout the day in the Alexa app during the failure. How does this all work? Alexa is powered by Amazon Web Services servers. These servers store data about your lamps, about your routines, about your Alexa usage and, indeed, about how to control your devices. Almost nothing is really stored on any given Echo device itself. Some small amounts of settings and a small amount of cache are utilized, but only to keep track of limited things for short periods of time. For example, if you’re playing music and pause, Alexa will keep track of that pause pointer for maybe 10-20 minutes max. After that time, it purges that resume information so that the stream can no longer resume.
All information about Alexa’s Smart Home devices is stored in the cloud on AWS. It also seems that state information about the lights (on, off, not responding) is also stored in AWS. When the connectivity stopped earlier on the 7th, that prevented connectivity from Alexa to those servers to determine the state of the information. It also prevented Alexa from controlling those specific devices handled strictly by Alexa. Because Alexa skills seemed to be handled by those servers, Alexa skills were unavailable also.
However, some services, like Ring, are also hosted on AWS. These servers seemed to have been impacted not only affecting Alexa’s interface to those services, but also preventing the use of Ring’s very own app to control its own services. Yes, it was a big outage.
This outage also affected many other servers and services unrelated to Alexa’s Smart Home systems. So, yes, it was a wide ranging, long lasting outage. In fact, as I type in this update, the outage may still be affecting some services. However, it seems that the Smart Home services may now be back online as of this writing. If you’re reading this days later, it’s likely all working again.
Smart Home Devices and Local Management
Using a hub Smart Home system like the Philips Hue hub system can allow for local management of equipment without the need for continuous internet. This means that if the Internet is offline for a period of time, you can still control your lighting with the Philips Hue app using local control. While you can control your lights with your switch, it’s just as important to be able to control your lighting even if your Internet goes down temporarily.
What this all means is that investing into a system like a Philips Hue hub and Philips Hue lights allows your smart lighting system to remain functional even if your Internet services goes down. In this case, Philips Hue didn’t go down and neither did my Internet. Instead, what went down was part of Amazon’s infrastructure and systems. This had an impact on much of Alexa and Alexa’s control over Smart Home devices. However, even though this was true of Alexa skills and Alexa controlled devices, Philips Hue remained functional all throughout.
That doesn’t necessarily mean that investing in a Philips Hue system is the best choice, but clearly in this instance it was a better choice than investing in the cheaper Alexa-only bulbs, which remained nonfunctional throughout the outage.
If there’s any caveat here, it’s that Smart Home systems are still subject to outages when services like AWS go belly up for a time. If you’re really wanting to maintain the ability to control your lights during such outages, then investing in a system like Philips Hue, which seems to be able to weather such outage storms, is the best of all worlds. Unfortunately, the Alexa only Sengled Bluetooth bulbs were the absolute worst choice for this type of AWS outage.
↩︎
Rant Time: Google doesn’t understand COPPA
 We all know what Google is, but what is COPPA? COPPA stands for the Children’s Online Privacy Protection Act and is legislation designed to incidentally protect children by protecting their personal data given to web site operators. YouTube has recently made a platform change allegedly around COPPA, but it is entirely misguided. It also shows that Google doesn’t fundamentally understand the COPPA legislation. Let’s explore.
We all know what Google is, but what is COPPA? COPPA stands for the Children’s Online Privacy Protection Act and is legislation designed to incidentally protect children by protecting their personal data given to web site operators. YouTube has recently made a platform change allegedly around COPPA, but it is entirely misguided. It also shows that Google doesn’t fundamentally understand the COPPA legislation. Let’s explore.
COPPA — What it isn’t
The COPPA body of legislation is intended to protect how and when a child’s personal data may be collected, stored, used and processed by web site operators. It has very specific verbiage describing how and when such data can be collected and used. It is, by its very nature, a data protection and privacy act. It protects the data itself… and, by extension, the protection of that data hopes to protect the child. This Act isn’t intended to protect the child directly and it is misguided to assume that it does. COPPA protects personal private data of children.
By the above, that means that the child is incidentally protected by how their collected data can (or cannot) be used. For the purposes of COPPA, a “child” is defined to be any person under the age of 13. Let’s look at a small portion of the body of this text.
General requirements. It shall be unlawful for any operator of a Web site or online service directed to children, or any operator that has actual knowledge that it is collecting or maintaining personal information from a child, to collect personal information from a child in a manner that violates the regulations prescribed under this part. Generally, under this part, an operator must:
(a) Provide notice on the Web site or online service of what information it collects from children, how it uses such information, and its disclosure practices for such information (§312.4(b));
(b) Obtain verifiable parental consent prior to any collection, use, and/or disclosure of personal information from children (§312.5);
(c) Provide a reasonable means for a parent to review the personal information collected from a child and to refuse to permit its further use or maintenance (§312.6);
(d) Not condition a child’s participation in a game, the offering of a prize, or another activity on the child disclosing more personal information than is reasonably necessary to participate in such activity (§312.7); and
(e) Establish and maintain reasonable procedures to protect the confidentiality, security, and integrity of personal information collected from children (§312.8).
This pretty much sums up the tone for what follows in the body text of this legislation. What it essentially states is all about “data collection” and what you (as a web site operator) must do specifically if you intend to collect specific data from someone under the age of 13… and, more specifically, what data you can and cannot collect.
YouTube and Google’s Misunderstanding of COPPA
YouTube’s parent company is Google. That means that I may essentially interchange “Google” for “YouTube” because both are one-in-the-same company. With that said, let’s understand how Google / YouTube fundamentally does not understand the COPPA body of legislation.
Google has recently rolled out a new feature to its YouTube content creators. It is a checkbox both as a channel wide setting and as an individual video setting. This setting sets a flag whether the video is targeted towards children or not (see image below for this setting’s details). Let’s understand Google’s misunderstanding of COPPA.
COPPA is a data protection act. It is not a child protection act. Sure, it incidentally protects children because of what is allowed to be collected, stored and processed, but make no mistake, it protects collected data directly, not children. With that said, checking a box on a video whether it is appropriate for children has nothing whatever to do with data collection. Let’s understand why.
Google has, many years ago in fact, already implemented a system to prevent “children” (as defined by COPPA) to sign up for and use Google’s platforms. What that means is when someone signs up for a Google account, that person is asked questions to ascertain the person’s age. If that age is identified as under 13, that account is classified by Google as in use by a “child”. Once Google identifies a child, it is then obligated to uphold ALL laws governed by COPPA (and other applicable child privacy laws) … that includes all data collection practices required by COPPA and other applicable laws. It can also then further apply Google related children protections against that account (i.e. to prevent the child from viewing inappropriate content on YouTube). Google would have needed to uphold these data privacy laws since the year 2000, when COPPA was enacted. If Google has failed to protect a child’s collected data or failed to uphold COPPA’s other provisions, then that’s on Google. It is also a situation firmly between Google and the FTC … the governmental body tasked with enforcing the COPPA legislation. Google solely collects the data. Therefore, it is exclusively on Google if that data is used or collected in inappropriate ways, counter to COPPA’s requirements.
YouTube’s newest “not appropriate for children” flag
As of November 2019, YouTube has implemented a new flag for YouTube content creators. The channel-wide setting looks like so:
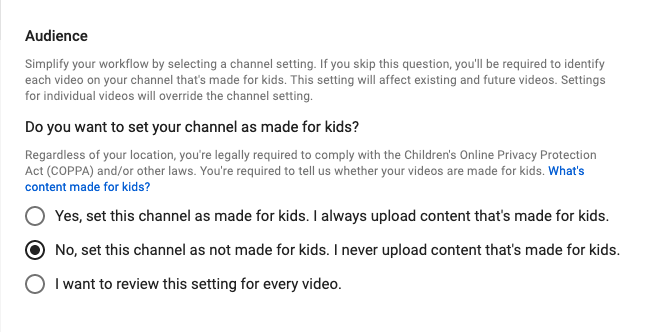
This setting, for all intents and purposes, isn’t related to COPPA. COPPA doesn’t care whether video content is targeted towards children. COPPA cares about how data is collected from children and how that data is then used by web sites. COPPA is, as I said above, all about data collection practices, not about whether content is targeted towards children.
Let’s understand that in the visual entertainment area, there are already ratings systems which apply. Systems such as the ESRB ratings system founded in 1994. This system specifically sets ratings for video games depending on the types of content contained within. For TV shows, there is the TV Parental Guidelines which began in 1996 and was proposed between the US Congress, the TV industry and FCC. These guidelines rate TV shows such as TV-Y, TV-14 or TV-MA depending, again, on the content within. This was mandated in 1997 by the US Government due to its stranglehold on TV broadcast licenses. For theatrical films, there’s the MPAA’s movie ratings system which began in 1968. So, it’s not as if there aren’t already effective content ratings systems available. These voluntary systems have been in place for many years already.
For YouTube, marking your channel or video content as “made for kids” has nothing whatever to do with COPPA legislated data collection practices.
YouTube Creators
Here is exactly where we see Google and YouTube’s fundamental misunderstanding of COPPA. COPPA is about the protection and collection of data from children. Google collects, stores and uses this and all data it collects. YouTube creators have very, very limited access to any of this Google-collected data. YouTube creators have no hand in its collection or its use. Google controls all of the data collection on YouTube. With the exception of comments and the list of subscribers of a channel, the majority of the data collected and supplied by Google to the creators is almost exclusively limited to aggregate unpersonalized statistical data. Even then, this data can be inaccurate depending on what the Google account ID stated when they signed up. Still, the limited personal subscriber data it does supply to content creators is limited to the subscriber’s ID only. Google offers its content creators no access to deeper personal data, not even the age of its subscribers.
Further, Google (and pretty much every other web site) relies on truthfulness when people sign up for services. Google does not in any way verify the information given to Google during the signup process or that this information is in any way accurate or truthful. Indeed, Google doesn’t even verify the identity of the person using the account or even require the use of real names. The only time Google does ANY level of identity verification is when using Google Wallet. Even then, it’s only as a result of needing identity verification due to possible credit card fraud issues. Google Wallet is a pointless service that many other payment systems do better, such as Apple Pay, Amazon Checkout and, yes, PayPal. I digress.
With that said, Google is solely responsible for all data collection practices associated with YouTube (and its other properties) including storing, processing and managing of that data. YouTube creators have no control over what YouTube (or Google) chooses to collect, store or disseminate. Indeed, YouTube creators have no control over YouTube’s data collection or storage practices whatsoever.
This new alleged “COPPA mechanism” that YouTube has implemented has nothing whatever to do with data collection practices and everything to do with content which might be targeted towards “children”. Right now, this limited mechanism is pretty much a binary system (a very limited system). The channel either does or it doesn’t target content towards children (either channel as a whole or video by video). It’s entirely unclear what happens when you do or don’t via YouTube, though some creators have had seeming bad luck with their content, which has been manually reviewed by YouTube staff and misclassified as “for children” when the content clearly is not. These manual overrides have even run counter to the global channel settings, which have been set to “No, set this channel as not made for kids.”
Clearly, this new mechanism has nothing to do with data collection and everything to do with classifying which content is suitable for children and which isn’t. This defines a …
Ratings System
Ratings systems in entertainment content are nothing new. TV has had a content rating systems since the mid 90s. Movies have had ratings systems since the late 60s. Video games have had them since the mid 90s. COPPA, on the other hand, has entirely nothing to do with ratings or content. It is legislation that protects children by protecting their data. It’s pretty straightforward what COPPA covers, but one thing it does not cover is whether video content is appropriate to be viewed by children. Indeed, COPPA isn’t a ratings system. It is child data protection legislation.
How YouTube got this law’s interpretation so entirely wrong is anyone’s guess. I can’t even fathom how Google could have been led this astray. Perhaps Google’s very own lawyers are simply inept and not at all versed in COPPA? I have no idea… but whatever led YouTube’s developers to thinking the above mechanism in any way relates to COPPA is entirely wrong thinking. No where does COPPA legislate YouTube video content appropriateness. Categorizing content is entirely up to a ratings system to handle.
Indeed, YouTube is trudging on very thin ice with the FTC. Not only did they interpret the COPPA legislation completely wrong, they have implemented “a fix” even more wrongly. What Google and YouTube has done is shoot themselves in the foot… not once, but twice. The second time is that Google has fully admitted that they don’t even have a functional working ratings system. Indeed, it doesn’t… and now everyone knows it.
Google has now additionally admitted that children under the age of 13 use YouTube by the addition of this “new” mechanism. With this one mechanism, Google has admitted to many things about children using its platform… which means YouTube and Google are both now in the hot seat with regards to COPPA. They must now completely ensure that YouTube (and Google by extension) is fully and solely complying with the letter of COPPA’s verbiage by collecting children’s data.
YouTube Creators Part II
YouTube creators have no control over what Google collects from its users, that’s crystal clear. YouTube creators also don’t have access to view most of this data or access to modify anything related to this data collection system. Only Google has that level of access. Because Google controls its own data collection practices, it is on Google to protect any personal information it may have received by children using its platform.
That also means that content creators should be entirely immune from prosecution over such data collection practices… after all, the creators don’t own or control Google’s data collection systems.
This new YouTube mechanism seems to imply that creators have some level of liability and/or culpability for Google’s collection practices, when creators simply and clearly do not. Even the FTC made a striking statement that they may try to “go after” content creators. I’m not even sure how that’s possible under COPPA. Content creators don’t collect, store or manage data about children, regardless of the content that they create. The only thing content creators control is appropriateness of the content towards children… and that has nothing to do with COPPA and everything to do with a ratings system… a system that Google does not even have in place within YouTube.
Content creators, however, can voluntarily label their content as TV-MA or whatever they deem is appropriate based on the TV Parental Guidelines. After all, YouTube is more like TV than it is like a video game. Therefore, YouTube should offer and have in place the same ratings system as is listed in the TV Parental Guidelines. This recent COPPA-attributed change is actually YouTube’s efforts at enacting a content ratings system, albeit an extremely poor attempt at one. As I said, creators can only specify the age appropriateness of the content that they create. YouTube is simply the platform where it is shown.
FTC going after YouTube Creators?
Google controls its data collections systems, not its content creators (though YouTube does hold leverage over whether content is or remains monetized). What that means is that it makes absolutely no sense for the FTC to legally go after content creators based on violations of COPPA. There may be other legislation they can lean on, but COPPA isn’t it. COPPA also isn’t intended to be a “catch all” piece of legislation to protect children’s behaviors on the Internet. It is intended to protect how data is collected and used by children under 13 years of age… that’s it. COPPA isn’t intended to be used as a “ratings system” for appropriateness by video sharing platforms like YouTube.
I can’t see even one judge accepting, let alone prosecuting such a clear cut case of legal abuse of the justice system. Going after Google for COPPA violations? Sure. They stored and collected that data. Going after the YouTube content creators? No, I don’t think so. They created a video and uploaded it, but that had nothing whatever to do with how Google controls, manages or collects data from children.
If the US Federal Government wants to create law to manage appropriateness of Internet content, then they need to draft it up and pass it. COPPA isn’t intended for that purpose. Voluntary ratings systems have been in place for years including within motion pictures, TV and now video games. So then why is YouTube immune from such rating systems? Indeed, it’s time YouTube was forced to implement a proper ratings system instead of this haphazard binary system under the false guise of COPPA.
Content Creator Advice
If you are a YouTube content creator (or create on any other online platform), you should take advantage of the thumbnail and describe the audience your content targets. The easiest way to do this is to use the same ratings system implemented by the TV Parental Guidance system… such as TV-Y, TV-14 and TV-MA. Placing this information firmly on the thumbnail and also placing it onto the video at the beginning of your video explicitly states towards which age group and audience your content is targeted. By voluntarily rating not only the thumbnail, but also the content itself in the first 5 minutes of the video opening, your video cannot be misconstrued for any other group or audience. This means that even though your video is not intended for children, placing the TV Parental Guidance rating literally onto the video intentionally states that fact in plain sight.
If a YouTube employee manually reclassifies your video as being “for children” even when it isn’t, labeling your content in the video’s opening as TV-MA explicitly states that the program is not suitable for children. You might even create an additional disclaimer as some TV programs do stating:
This content is not suitable for all audiences. Some content may be considered disturbing or controversial. Viewer or parental discretion is advised.
Labeling your video means that even the FTC can’t argue that your video somehow inappropriately targeted children… even though this new YouTube system has nothing to do with COPPA. Be cautious, use common sense and use best practices when creating and uploading videos to YouTube. YouTube isn’t there to protect you, the creator. The site is there to protect YouTube and Google. In this case, this new creator feature is entirely misguided as a COPPA helper, when it is clearly intended to be a ratings system.
Before you go…
One last thing… Google controls everything about the YouTube platform including the “recommended” lists of videos. If, for whatever reason, Google chooses to promote a specific video towards an unintended audience, the YouTube creator has no control over this fact. In point of fact, the content creator has almost no control over any promotion or placement of their video within YouTube. The only exception is if YouTube allows for paid promotion of video content (and they probably do). After all, YouTube is in it for the $$$. If you’re willing to throw some of your money at Google, I’m quite sure they’d be willing to help you out. Short of paying Google for video placement, however, all non-paid placement is entirely at the sole discretion of Google. The YouTube creator has no control over their video’s placement within “recommended” lists or anywhere else on YouTube.
↩︎
Software Engineering and Architecture
 Here’s a subject of which I’m all too familiar and is in need of commentary. Since my profession is technical in nature, I’ve definitely run into various issues regarding software engineering, systems architecture and operations. Let’s Explore.
Here’s a subject of which I’m all too familiar and is in need of commentary. Since my profession is technical in nature, I’ve definitely run into various issues regarding software engineering, systems architecture and operations. Let’s Explore.
Software Engineering as a Profession
One thing that software engineers like is to be able to develop their code on their local laptops and computers. That’s great for rapid development, but it causes many problems later, particularly when it comes to security, deployment, systems architecture and operations.
For a systems engineer / devops engineer, the problem arises when that code needs to be productionalized. This is fundamentally a problem with pretty much any newly designed software system.
Having come from from a background of systems administration, systems engineering and devops, there are lots to be considered when wanting to deploy freshly designed code.
Designing in a Bubble
I’ve worked in many companies where development occurs offline on a notebook or desktop computer. The software engineer has built out a workable environment on their local system. The problem is, this local eneironment doesn’t take into account certain constraints which may be in place in a production environment such as internal firewalls, ACLs, web caching systems, software version differences, lack of compilers and other such security or software constraints.
What this means is that far too many times, deploying the code for the first time is fraught with problems. Specifically, problems that were not encountered on the engineer’s notebook… and problems that sometimes fail extremely bad. In fact, many of these failures are sometimes silent (the worst kind), where everything looks like it’s functioning normally, but the code is sending its data into a black hole and nothing is actually working.
This is the fundamental problem with designing in a bubble without any constraints.
I understand that building something new is fun and challenging, but not taking into account the constraints the software will be under when finally deployed is naive at best and reckless at the very worse. It also makes life as a systems engineer / devops engineer a living hell for several months until all of these little failures are sewn shut.
It’s like receiving a garment that looks complete, but on inspection, you find a bunch of holes all over that all need to be fixed before it can be worn.
Engineering as a Team
To me, this is situation means that software engineer is not a team player. They might be playing on the engineering team, but they’re not playing on the company team. Part of software design is designing for the full use case of the software, including not only code authoring, but systems deployment.
If systems deployment isn’t your specialty as a software engineer, then bring in a systems engineer and/or devops engineer to help guide your code during the development phase. Designing without taking the full scope of that software release into consideration means you didn’t earn your salary and you’re not a very good software engineer.
Yet, Silicon Valley is willing to pay “Principal Engineers” top dollar for these folks failing to do their jobs.
Building and Rebuilding
It’s an entirely a waste of time to get to the end of a software development cycle and claim “code complete” when that code is nowhere near complete. I’ve had so many situations where software engineers toss their code to us as complete and expect the systems engineer to magically make it all work.
It doesn’t work that way. Code works when it’s written in combination with understanding of the architecture where it will be deployed. Only then can the code be 100% complete because only then will it deploy and function without problems. Until that point is reached, it cannot be considered “code complete”.
Docker and Containers
More and more, systems engineers want to get out of the long drawn out business of integrating square code into a round production hole, eventually after much time has passed, molding the code into that round hole is possible. This usually takes months. Months that could have been avoided if the software engineer had designed the code in an environment where the production constraints exist.
That’s part of the reason for containers like Docker. When a container like Docker is used, the whole container can then be deployed without thought to square pegs in round holes. Instead, whatever flaws are in the Docker container are there for all to see because the developer put it there.
In other words, the middle folks who take code from engineering and mold it onto production gear don’t relish the thought of ironing out hundreds of glitchy problems until it seamlessly all works. Sure, it’s a job, but at some level it’s also a bit janitorial, wasteful and a unnecessary.
Planning
Part of the reason for these problems is the delineation between the engineering teams and the production operations teams. Because many organizations separate these two functional teams, it forces the above problem. Instead, these two teams should be merged into one and work together from project and code inception.
When a new project needs code to be built that will eventually be deployed, the production team should be there to move the software architecture onto the right path and be able to choose the correct path for that code all throughout its design and building phases. In fact, every company should mandate that its software engineers be a client of operations team. Meaning, they’re writing code for operations, not the customer (even though the features eventually benefit the customer).
The point here is that the code’s functionality is designed for the customer, but the deploying and running that code is entirely for the operations team. Yet, so many software engineers don’t even give a single thought to how much the operations team will be required support that code going forward.
Operational Support
For every component needed to support a specific piece of software, there needs to be a likewise knowledgeable person on the operations team to support that component. Not only do they need to understand that it exists in the environment, the need to understand its failure states, its recovery strategies, its backup strategies, its monitoring strategies and everything else in between.
This is also yet another problem that software engineers typically fail to address in their code design. Ultimately, your code isn’t just to run on your notebook for you. It must run on a set of equipment and systems that will serve perhaps millions of users. It must be written in ways that are fail safe, recoverable, redundant, scalable, monitorable, deployable and stable. These are the things that the operations team folks are concerned with and that’s what they are paid to do.
For each new code deployment, that makes the environment just that much more complex.
The Stacked Approach
This is an issue that happens over time. No software engineer wants to work on someone else’s code. Instead, it’s much easier to write something new and from scratch. It’s easy for software engineer, but it’s difficult for the operations team. As these new pieces of code get written and deployed, it drastically increases the technical debt and burden on the operations staff. Meaning, it pushes the problems off onto the operations team to continue supporting more and more and more components if none ever get rewritten or retired.
In one organization where I worked, we had such an approach to new code deployment. It made for a spider’s web mess of an environment. We had so many environments and so few operations staff to support it, the on-call staff were overwhelmed with the amount of incessant pages from so many of these components.
That’s partly because the environment was unstable, but that’s partly because it was a house of cards. You shift one card and the whole thing tumbles.
Software stacking might seem like a good strategy from an engineering perspective, but then the software engineers don’t have to first line support it. Sometimes they don’t have to support it at all. Yes, stacking makes code writing and deployment much simpler.
How many times can engineering team do this before the house of cards tumbles? Software stacking is not an ideal any software engineering team should endorse. In fact, it’s simply comes down to laziness. You’re a software engineer because writing code is hard, not because it is easy. You should always do the right thing even if it takes more time.
Burden Shifting
While this is related to software stacking, it is separate and must be discussed separately. We called this problem, “Throwing shit over the fence”. It happens a whole lot more often that one might like to realize. When designing in a bubble, it’s really easy to call “code complete” and “throw it all over the fence” as someone else’s problem.
While I understand this behavior, it has no place in any professionally run organization. Yet, I’ve seen so many engineering team managers endorse this practice. They simply want their team off of that project because “their job is done”, so they can move them onto the next project.
You can’t just throw shit over the fence and expect it all to just magically work on the production side. Worse, I’ve had software engineers actually ask my input into the use of specific software components in their software design. Then, when their project failed because that component didn’t work properly, they threw me under the bus for that choice. Nope, that not my issue. If your code doesn’t work, that’s a coding and architecture problem, not a component problem. If that open source component didn’t work in real life for other organizations, it wouldn’t be distributed around the world. If a software engineer can’t make that component work properly, that’s a coding and software design problem, not an integration or operational problem. Choosing software components should be the software engineer’s choice to use whatever is necessary to make their software system work correctly.
Operations Team
The operations team is the lifeblood of any organization. If the operations team isn’t given the tools to get their job done properly, that’s a problem with the organization as a whole. The operations team is the third hand recipient of someone else’s work. We step in and fix problems many times without any knowledge of the component or the software. We do this sometimes by deductive logic, trial and error, sometimes by documentation (if it exists) and sometimes with the help of a software engineer on the phone.
We use all available avenues at our disposal to get that software functioning. In the middle of the night the flow of information can be limited. This means longer troubleshooting times, depending on the skill level of the person triaging the situation.
Many organizations treat its operations team as a bane, as a burden, as something that shouldn’t exist, but does out of necessity. Instead of treating the operations team as second class citizens, treat this team with all of the importance that it deserves. This degrading view typically comes top down from the management team. The operations team is not a burden nor is it simply there out of necessity. It exists to keep your organization operational and functioning. It keeps customer data accessible, reliable, redundant and available. It is responsible for long term backups, storage and retrieval. It’s responsible for the security of that data and making sure spying eyes can’t get to it. It is ultimately responsible to make sure the customer experience remains at a high excellence standard.
If you recognize this problem in your organization, it’s on you to try and make change here. Operations exists because the company needs that job role. Computers don’t run themselves. They run because of dedicated personnel who make it their job and passion to make sure those computers stay online, accessible and remain 100% available.
Your company’s uptime metrics are directly impacted by the quality of your operations team staff members. These are the folks using the digital equivalent of chewing gum and shoelaces to keep the system operating. They spend many a sleepless night keeping these systems online. And, they do so without much, if any thanks. It’s all simply part of the job.
Software Engineer and Care
It’s on each and every software engineer to care about their fellow co-workers. Tossing code over the fence assuming there’s someone on the other side to catch it is insane. It’s an insanity that has run for far too long in many organizations. It’s an insanity that needs to be stopped and the trend needs to reverse.
In fact, by merging the software engineering and operations teams into one, it will stop. It will stop by merit of having the same bosses operating both teams. I’m not talking about at a VP level only. I’m talking about software engineering managers need to take on the operational burden of the components they design and build. They need to understand and handle day-to-day operations of these components. They need to wear pagers and understand just how much operational work their component is.
Only then can engineering organizations change for the positive.
As always, if you can identify with what you’ve read, I encourage you to like and leave a comment below. Please share with your friends as well.
↩︎







1 comment